The mighty oak from an acorn towers
Back at the dawn of the web, the URL was created as a way of identifying and locating resources. A key characteristic of URLs on the web was the notion of a hierarchy, or tree, of resources defined by the path of the URL.
The path component contains data, usually organized in hierarchical form RFC3986
Tree structures are a powerful concept used in many software projects. The path structure in a URL enables an HTTP API to represent a virtually unlimited number of resources in a well organized manner.
Design with intent
In an earlier blog post I discussed a taxonomy for designing URL path segments. URLs are a significant part of the user experience for developers consuming an API and spending time designing those URLs is time well spent. Consistency within an API and with common industry conventions makes an API significantly easier to work with. While client applications are required to treat URLs as opaque strings, the humans in front of the keyboards can infer extensive amounts of information from the words in the URL and its shape.
A picture is worth a thousand words
Being able to grok a single URL is one aspect of understanding an API design. However, it is also valuable to be able to get a big picture view of the resources available within an API. Looking at a flat list of method and URL pairs, as is shown in the defacto Swagger UI, can be overwhelming for large API surface areas. By taking advantage of the tree structure of the URL path, it is possible to create a more consumable presentation of the API surface area. Here is a rendering of the OpenAI HTTP API.
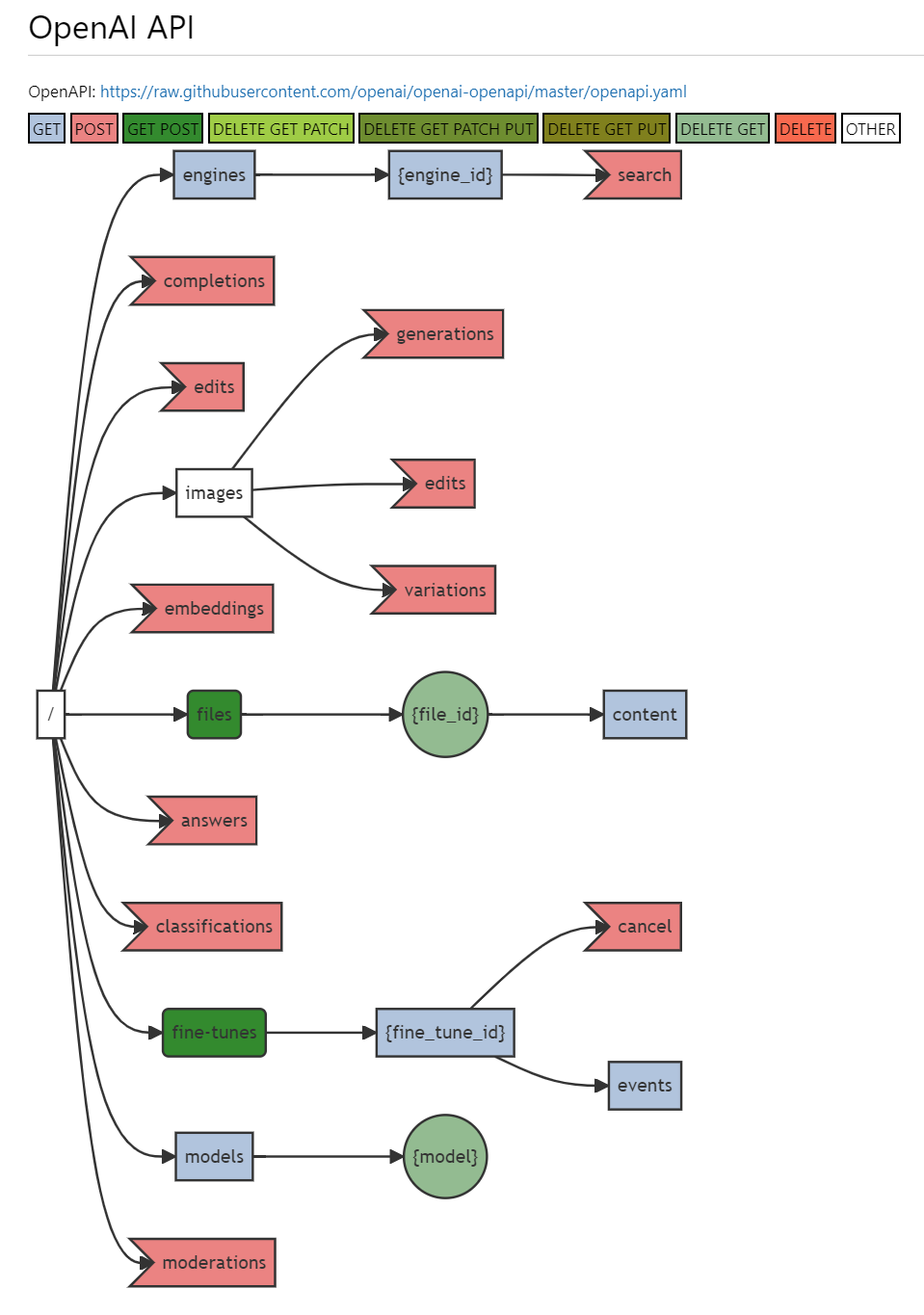
There are other examples of popular APIs rendered here. These API tree diagrams are generated by creating Mermaid syntax from OpenAPI descriptions.
Behavioural types
When creating the API tree diagrams, I recognized that it would be useful to know what methods are supported on resources. I wanted to annotate the resources with some kind of symbol to indicate a supported method. However, the constraints of Mermaid diagrams limited my options. I resorted to selecting a colour and shape to represent a set of supported methods. e.g. resources that support just GET and POST are green and use a rectangle with rounded corners.
In using this categorization mechanism, I realized that it effectively created a new kind of behavioural typing system that could be used to further qualify the API anatomy taxonomy. For example, a path segment can represent a collection of resources, but those collections can have very different behaviours.
The files collection in the OpenAI API can be enumerated and added to.

Whereas, in the Spotify API, the shows and tracks collection are read-only. The users collection does not support reading or adding, but the playlists collection allows enumeration and adding.
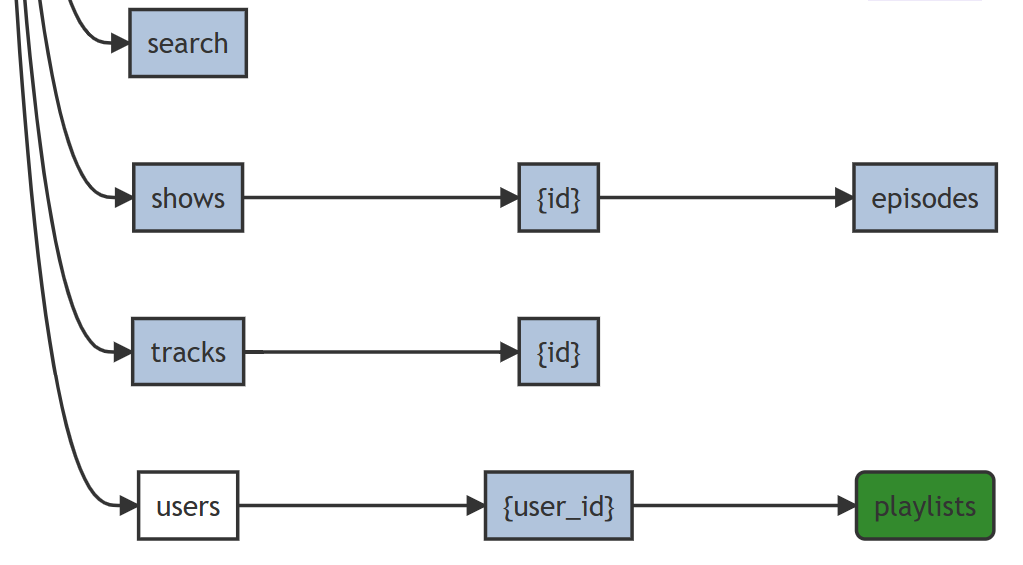
The ability to see structure of the API tree and see similarities and differences between the behaviour of resources is an efficient way to quickly learn the capabilities of an API. Once a viewer has some familiarity with significance of the colours and shapes, it becomes immediately apparent that the Plaid API is designed as an RPC API that only supports the POST method on leaf nodes.
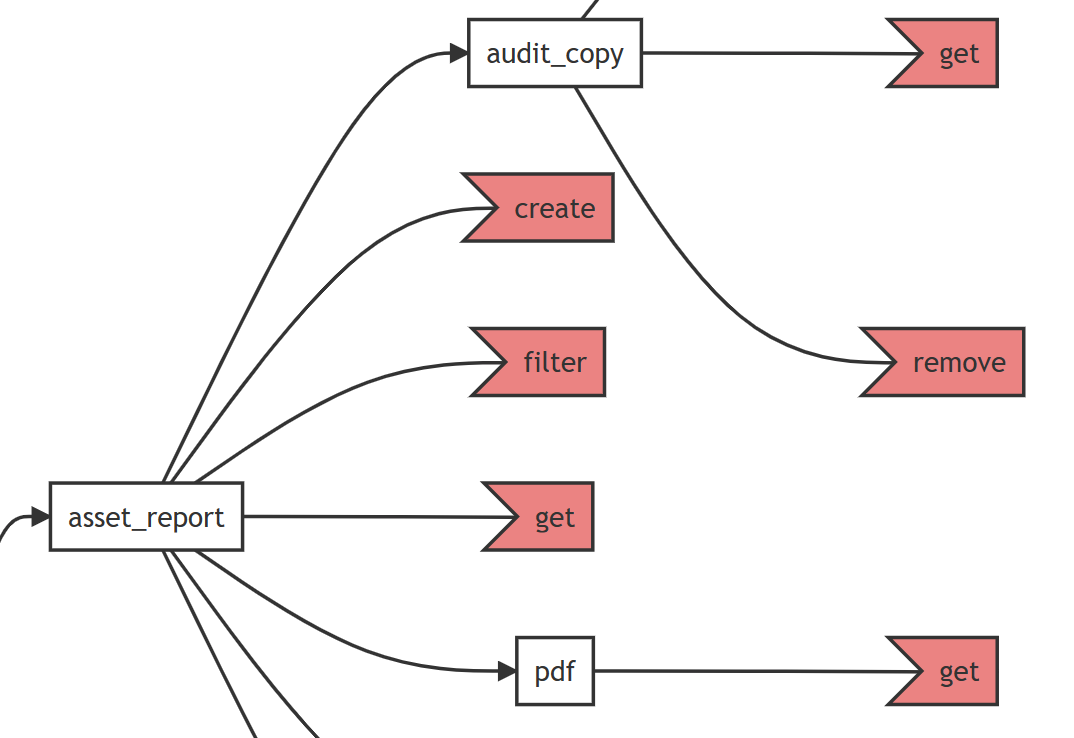
Stop clear cutting your API trees
Documentation and SDK generation are a big part of the developer experience for consuming APIs. Unfortunately when designing these artifacts we have relied too heavily on our past experience working with local component APIs. The effect of this has been the practice of creating small API surface areas whose set of resources can be flattened into a set of method calls for an SDK client, or a very shallow table of contents for API documentation. APIs with a large number of resources do not flatten easily; method names end up being long and cumbersome and documentation pages become difficult to find.
A good example of the tension between developers using the URL hierarchy for their API design and the limitations of documentation infrastructure is shown below in one of the Google cloud APIs.
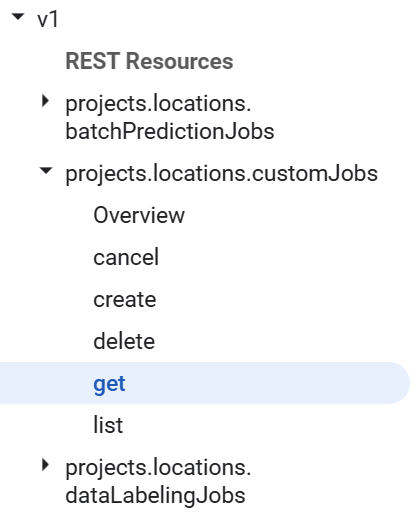
Due to the limited nesting of the table of contents the index uses dots to create compound entries. There are many other examples of API documentation where you can see the design of the resource hierarchy is lost when it is shoehorned into existing infrastructure.
My day job involves working on Microsoft Graph which is an API that has tens of thousands of resources. Converting the HTTP methods for every resource into a method on an client object would have produced a very poor developer experience. To manage the size and depth of the API tree, we created client SDKs that contain a tree of classes that match the API path segments.
e.g. to call the URL /users/{email}/mailfolders/{folder}/messages/{messageId}/attachments the following code is possible.
var attachments = await _graphClient
.Users[email]
.MailFolders[folder]
.Messages[messageId]
.Attachments
.GetAsync();
We built the Kiota API client code generator to enable anyone with an OpenAPI description of their API to be able to generate client code that mimics the shape of the API tree.
Go with the grain
Hopefully developers have spent time designing the paths to their API resources. Ignoring, hiding, or changing that design structure when creating the developer experience is counterproductive. If feedback from customers indicates that the design is confusing, or could be improved in some way, then evolve the API shape into something better. Do not "fix it" by hiding the problems using documentation or client libraries. The shape of your URLs is the UI of your product. Put the effort into designing it right and then put that UI front and center in every experience.
